Empilhando Trabalhos
Repositório dos trabalhos para a matéria de estrutura de dados.
Análise de Desempenho: Fibonacci Recursivo vs. Iterativo
Este projeto realiza uma análise comparativa do desempenho de duas implementações para o cálculo da sequência de Fibonacci: uma abordagem recursiva e uma iterativa. A análise é feita medindo o tempo de execução de cada algoritmo para uma gama de valores de entrada n, gerando dados brutos em um arquivo .csv e, em seguida, visualizando esses dados em gráficos.
Implementação
O projeto é dividido em duas partes principais: um programa em C para a lógica dos algoritmos e a medição de tempo, e um script em Python para a visualização dos dados.
1. Lógica dos Algoritmos e Coleta de Dados (C)
O código-fonte em C é responsável por:
- Implementar as duas versões da função Fibonacci:
fibonacci_recursive: Segue a definição matemática $F(n) = F(n-1) + F(n-2)$. Como vimos em aula, esse método gera uma árvore de recursão. Logo, como, para camada chamada de $F(n)$, chamamos outras duas, esperamos $O(2^n)$.fibonacci_iterative: Utiliza um laço para calcular os valores da sequência de forma sequencial. Como o laço temnrepetições, esperamos $O(n)$.
- Medir o Tempo de Execução:
- As funções
calculate_recursive_timeecalculate_iterative_timeusam a funçãoclock()da biblioteca<time.h>para medir o tempo de processador gasto. - Para obter uma medição mais estável, cada função é executada um grande número de vezes (
RECURSIVE_REPEATSeITERATIVE_REPEATS), e o tempo médio por execução é calculado.
- As funções
- Gerar Dados para Análise:
- A função
data_generate()itera sobre valores den(de 0 aN_MAX), chama as funções de medição de tempo para ambas as implementações e escreve os resultados (n,tempo_recursivo,tempo_iterativo) em um arquivo chamadodata.csv.
- A função
2. Geração e Visualização de Gráficos (Python)
O script graph.py utiliza as seguintes bibliotecas:
- Pandas: Para ler e manipular os dados do arquivo
data.csvde forma eficiente. - Matplotlib e SciencePlots: Para criar gráficos de alta qualidade e com estilo científico.
O script gera quatro gráficos distintos para analisar os dados
Resultados e Análise
A execução do código em C gera os dados de tempo, e o script em Python produz os seguintes gráficos.
Tempo de Execução: Versão Recursiva
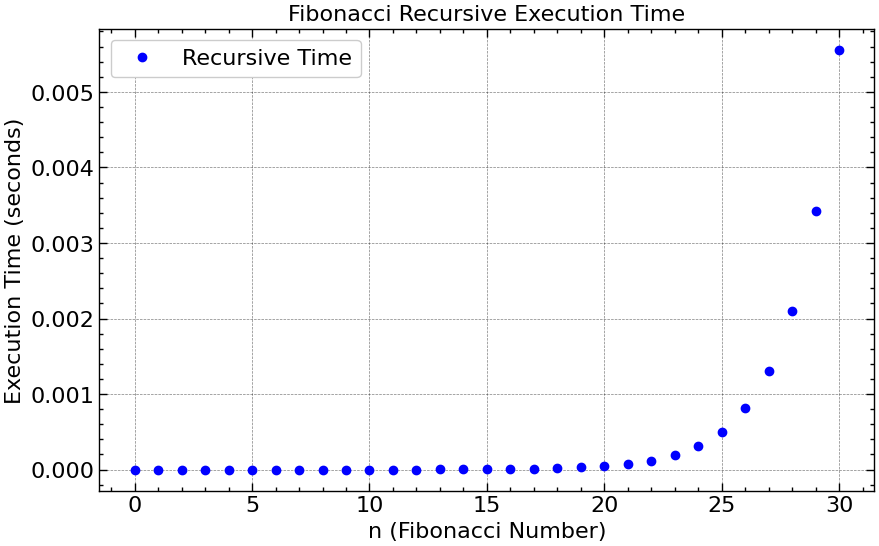
- Podemos ver um comportamento aparentemente exponencial
Tempo de Execução: Versão Iterativa
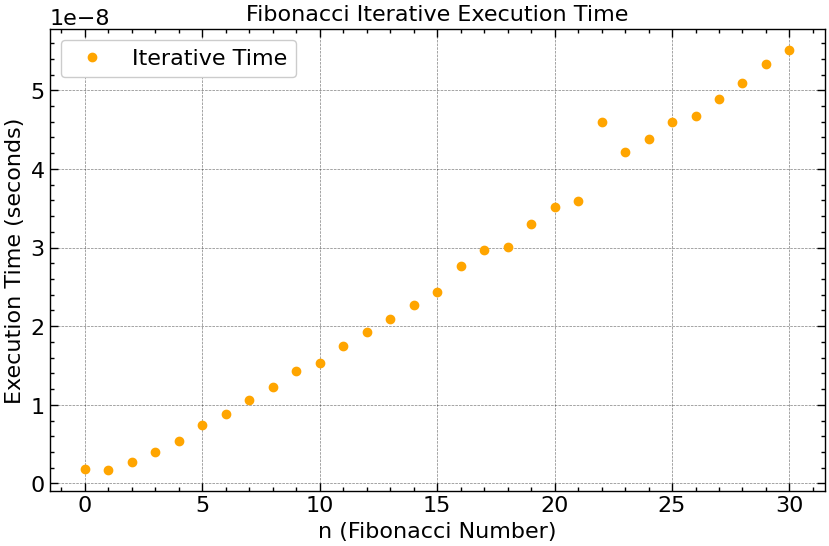
- A curva de tempo da versão iterativa se aproxima de uma reta, como esperado para $O(n)$ em escala linear
Comparativo em Escala Linear
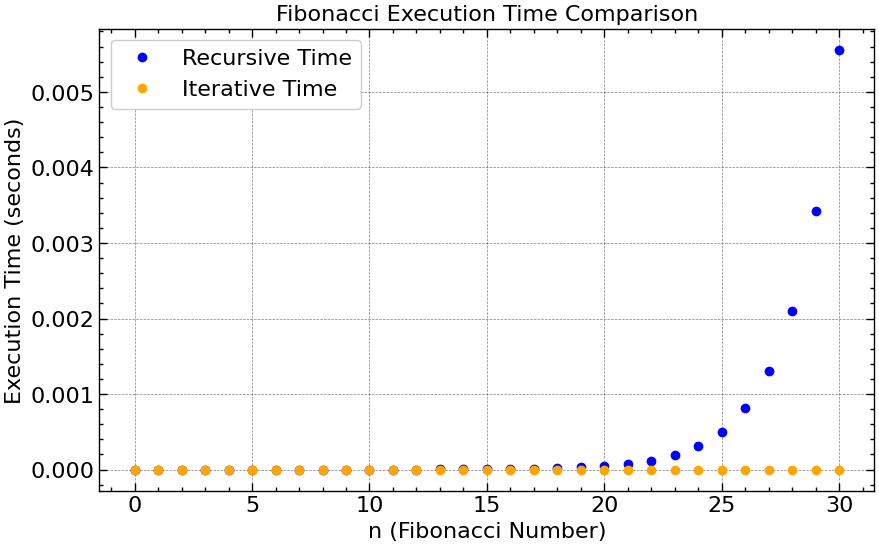
- Fica evidente, que, para o problema em questão, a versão iterativa é extremamente mais rápida para
ngrande
Comparativo em Escala Logarítmica
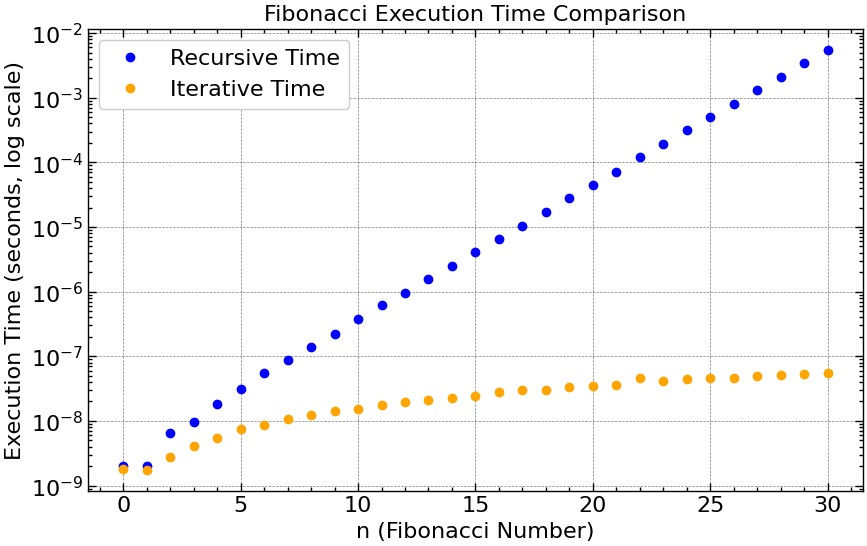
- A curva de tempo da versão recursiva se aproxima de uma reta, como esperado para $O(2^n)$ em escala logarítimica
Conclusão
Os dados confirmam o esperado: comportamento linear para a versão iterativa e comportamento exponencial para a recursiva.